FPGAs, a form of reconfigurable architectures, already power a large number of datacenter applications. With FPGA acceleration becoming mainstream, it is the perfect opportunity to think about programming models for designing next-generation high-performance hardware.
Moore’s law is in its death throes. With Global Foundries announcing that they are no longer pursuing 7nm production nodes, fabrication companies focusing on incremental improvements, and the end of the arguably more important Dennard scaling, we’re entering a new era where general purpose architectures are no longer the solution. Reconfigurable architectures are one of the hottest research topics and perhaps hold the key to application-specific hardware acceleration. However, without a sane programming model, reconfigurable architectures might not achieve the success they deserve.
Reconfigurable Architectures
Since the dawn of computer architecture, we’ve focused on building processors that are good at executing every conceivable program. The advances in pipelined designs, speculative and out-of-order execution all try to dynamically discover regularity and parallelism in arbitrary programs and execute them as fast as possible. The performance benefits of these technologies are inarguable. However, all good things come at a price. In their single-minded zealotry to improve single threaded performance, processors introduce an incredible amount of control overhead. Figure 1 shows the energy breakdown of executing an add instruction. The control dominates the cost of executing an instruction.
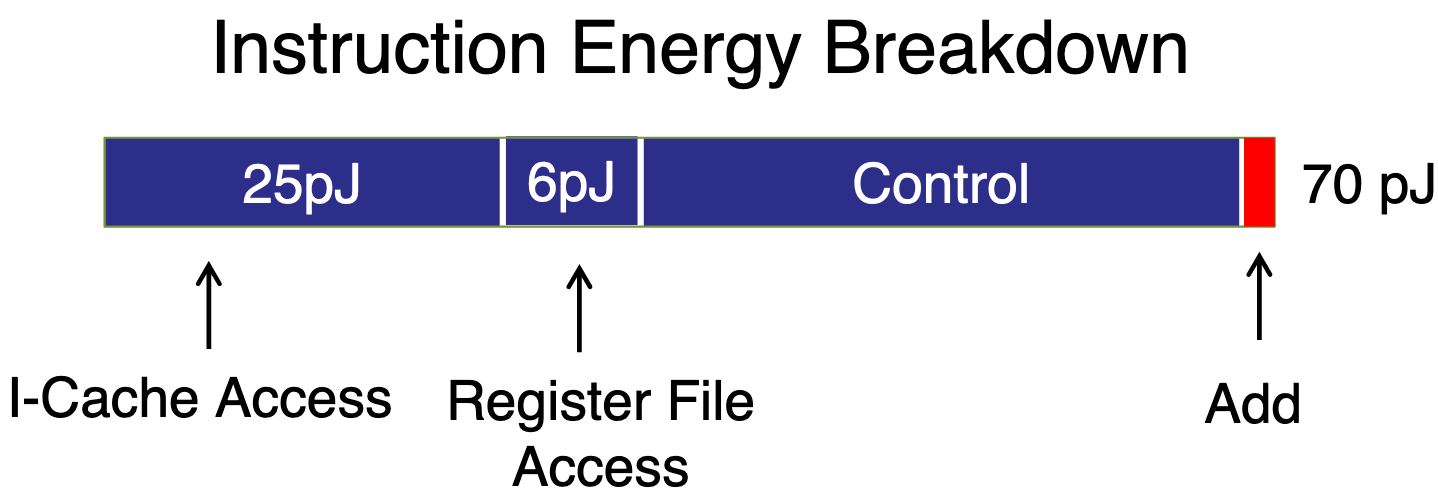
So while modern processors can execute arbitrary programs quickly, they leave a lot of room for improvement with an individual program. Instead of paying for the cost of the general control structures in every program, what if your processor could pay for the exactly the amount of control required to execute the current program. What if you could reconfigure your architecture based on the currently executing program? Reconfigurable architectures refers to the general class of architectures that allow some degree of application-specific reconfigurability. The term “reconfigurable architectures” is incredibly broad and spans everything from the reconfigurability of meshes in massive many-cores to bit-level reconfigurable architectures. In this post, we’ll be focusing on Field Programmable Gate Arrays (FPGAs) as a reconfigurable accelerator.
FPGAs as Computational Accelerators
FPGAs were initially developed as high-performance simulators for circuit designs. Testing a hardware design requires simulating its behavior over thousands of clock cycles. With larger and more complex, the computational power required to simulate and track the state of a design becomes increasingly hard. Unfortunately, simulating a hardware design on a traditional processor does not scale—imagine trying to simulate an i3 processor on a Pentium 4. FPGAs were designed as simulation accelerators. They provide bit-level reconfigurability which allows them to simulate wires and gates in a hardware design.
The bit-level reconfigurability also made FPGAs viable as a cheaper, low-volume alternate to application specific integrated circuits (ASICs). Instead of taping-out custom chips, FPGAs could be used to prototype and integrate such accelerators without paying for a full silicon tape-out. In domains like signal processing or networking, where real-time deadlines really matter and CPUs struggle to meet high-throughput requirements, FPGAs were successfully used as computational accelerators. The common thread in all of these use cases is that we really want to design custom circuits but don’t want to pay the costs of producing a whole new chip.
FPGAs happily chugged along in these niche roles for a long time without taking off in a big way. Researchers knew that FPGAs could play a big role as flexible accelerators but didn’t have a “killer app”. Between 2010-2016, an exceptional team of computer architects demonstrated that FPGAs could be used as computational accelerators inside datacenters through the Catapult project. Catapult, and its successor BrainWave, showed that not only can FPGAs significantly improve the performance of modern large-scale applications, they provide enough flexibility to be used in multiple domains, accelerating everything from Bing search, Azure cloud network, and most recently, ML models.
Other cloud services like AWS have jumped on this trend and now offer F1 instances which provide access to high-end FPGA units through AWS’s pay-what-you-use model.
FPGA Programming 101
Owing to its root as a hardware simulator, FPGA programming toolchains repurpose existing hardware design languages (HDLs). As a circuit simulator, this is a really good idea. You can simply take your preexisting hardware design and run it on an FPGA. I apologize to my architect friends. Running designs on an FPGA in reality can be an incredible challenge. FPGAs have different kinds of memory and performance characteristics. Most hardware design codebases are carefully engineered to separate FPGA-specific design decisions from the core design.
Unfortunately, when trying to run high-level application code the level of abstraction afforded by HDLs is far too low-level. Imagine trying to write a convolution kernel by specifying every wire connection into every adder and the computation that occurs at every clock cycle. Proponents of HDLs will point out that we can eek out every bit of performance from a low-level hardware design. However, this also means that design iteration times are much worse. It can take many weeks of engineering effort to implement and optimize a design.
I am by no means the first person to point this productivity-performance trade-off. Practitioners and researchers have created a multitude of HDLs to improve the level of abstraction: BlueSpec, SystemVerilog, PyMTL, Chisel, etc. all aim to use host languages to improve the level of abstraction in some manner. For example, Chisel is embedded in Scala and provides modularity and parameterization mechanisms using Scala’s type system. However, HDLs still fundamentally operate at the gate-and-wire level of abstraction. Chisel designs, after being typechecked by the Scala compiler, are expanded into a structural specification of the hardware design.
A more radical technique to lift the level of abstraction would be to specify how the computation occurs and use a compiler to generate the hardware for that specification. The architecture community has been exploring the idea of transforming behavioral (or functional) descriptions of computation into hardware designs. This is commonly referred to High-Level Synthesis (HLS) in the community.
High-Level Synthesis
High-Level Synthesis “Synthesis” is borrowed from hardware design workflows—circuits are synthesized into silicon. This is just a compiler. is the idea of compiling a computational description in a high-level programming language, Architects operate at the level of gates, wires, and clocks. C++ is a huge jump in abstractions. like C or C++, into an HDL like Verilog. HLS has been quite successful in a multitude of domains—everything from digital signal processing to machine learning accelerators has been implemented in HLS.
The semantic gap between a functional description and timed hardware structures is quite large. Hardware designs are timed because they explicitly describe the behavior of individual circuits at the granularity of clock cycles. An HLS compiler needs to transform the functional description into a data path, which describes the hardware structures that perform computations, and a control path, which describes the computation performed by components every cycle.
The promise of transforming any C++ program into hardware is absurd at its face. C++ programs dynamically allocate memory, use complicated control structures, and are notoriously hard to analyze. Compare this to physical hardware where memory sizes and control structures need to statically generated at compile time.
I’ll leave the specifics of where HLS fails for a future blog post. If you’re curious, dive into our paper on Dahlia which identifies some of these problems and shows how little bit of programming languages magic can help.
If you’re curious about this area, jump onto these cool blog posts and papers:
- FPGAs Have the Wrong Abstraction by Adrian Sampson.
- High-Level Synthesis for FPGAs: From Prototyping to Development.
- A Cloud-Scale Acceleration Architecture.
(If you’ve written a blog post on HLS-related stuff, email it to me so I can add it here!)
Thanks for Adrian Sampson and Alexa VanHattum for providing feedback on early drafts of this blog post.